6 PDF HandShake Dienstprogramme
6.1 pdfcat
Mit dem Programm „pdfcat“ können Sie PDF-Dateien auf dem Server in einzelne Seiten aufteilen oder mehrere PDF-Seiten zu einer Datei zusammenfügen. Die Verwendung von „pdfcat“ ist unentbehrlich, wenn Sie ein mehrseitiges Dokument haben, welches Sie in einem reinen EPSF- oder OPI-Workflow einsetzen möchten. Der OPI-Server erzeugt immer nur von der ersten Seite eines PDF-Dokuments ein Platzierungsbild. Wenn Sie also ein Platzierungsbild von der zweiten Seite eines Dokuments haben möchten, müssen Sie die gewünschte Seite extrahieren und als neue Einzelseiten-PDF-Datei sichern. Die nachfolgende Grafik zeigt die drei verschiedenen Programmodi, die alle unabhängig voneinander sind und sich gegenseitig ausschließen: Der Modus „Zusammenfügen“ verbindet die ausgewählten PDF-Dateien (oder Teile davon) zu einer neuen Datei, der Modus „Anhängen“ hängt die ausgewählten Dateien (oder Teile davon) an eine bestehende Datei an und der Modus „Extrahieren“ schreibt die ausgewählten Seiten eines existierenden Dokuments in neue Einzelseitendateien.
Jede PDF-Datei enthält eine Liste von Dateiinformationen, wie z. B. Verfasser, Erstellungsdatum, Änderungsdatum oder Bildprofile (optional). Außerdem kann eine PDF-Datei Sicherheitseinstellungen (optional), ein Liste von Lesezeichen (Inhaltsverzeichnis) und Anmerkungen wie Textfelder, Knöpfe usw. enthalten.
Das „pdfcat“-Programm organisiert und erstellt PDF-Dateien neu. Dabei werden die Dateiinformationen, Profile, Sicherheitseinstellungen, Lesezeichen und Anmerkungen wie folgt behandelt:
Wenn „pdfcat“ ein neues mehrseitiges Dokument erstellt (wie in der ersten Zeile der Abbildung gezeigt), erhält die neue Datei ihren eigenen Verfasser und ein Erstellungsdatum. Sie wird keine ICC-Profile beinhalten – auch wenn die Ursprungsdateien „getagged“ waren – und sie wird keine Sicherheitseinstellungen haben. Lesezeichen, falls in den Ursprungsdateien vorhanden, werden nicht in die neue Datei übernommen. Anmerkungen werden dagegen aus den ursprünglichen Dateien in das neu erzeugte Dokument übernommen.
Wenn „pdfcat“ Seiten und/oder Dokumente an eine bestehende PDF-Datei anhängt – wie in der zweiten Zeile der Abbildung gezeigt –, wird die Zieldatei (helios.pdf (neu)) alle Informationen enthalten, die schon in der Ursprungsdatei enthalten waren (helios.pdf). Dateiinformationen, Profile, Sicherheitseinstellungen, Lesezeichen und Anmerkungen bleiben unverändert. Informationen, die in den angehängten Dateien enthalten waren (Doc2 und Doc3), werden mit Ausnahme der Anmerkungen nicht in die Zieldatei übernommen sondern ignoriert.
Wenn „pdfcat“ ein Dokument in mehrere neue aufteilt – wie in der letzten Zeile der Abbildung gezeigt –, erben die neuen Einzelseitendokumente die Dateiinformationen, Profile, Anmerkungen und Sicherheitseinstellungen von der Originaldatei. Lesezeichen werden jedoch nicht in die Zieldateien kopiert. Bitte beachten Sie, dass „pdfcat“ keine Kommentare in die Finder-Information schreiben kann. Wenn die PDF-Dateien Profilinformationen enthalten, werden diese üblicherweise in der Finder-Information in Mac OS 9 oder über HELIOS Meta sowie in WebShare aufgelistet. Dieses Textfeld kann leer sein, wenn Sie PDF-Dateien mit „pdfcat“ erstellt haben, auch wenn die neuen Dateien Profilinformationen enthalten. In diesem Fall können Sie unser Acrobat Plug-in oder das ImageServer Programm „HELIOS ICC Tagger“ benutzen, um Profile sichtbar zu machen.
Für PDF-Dateien, die mit „pdfcat“ erstellt wurden, funktioniert die
automatische Layouterzeugung nicht. Sie müssen unsere Programme „opitouch“
oder „layout“ verwenden oder dt touch -E aufrufen, um
Platzierungsbilder von den neuen PDF-Dateien zu erzeugen. Alternativ können Sie den Ablauf mittels Script Server (Bestandteil
von ImageServer) automatisieren.

- Verwendung:
pdfcat [-v] -o <outDoc> <inDoc> ... pdfcat [-v] -a <outDoc> <inDoc> ... pdfcat [-v] -e <prefix> <inDoc> pdfcat -h
6.1.1 Optionen
- -v
Zeigt den Fortschritt während der Verarbeitung mit „pdfcat“ an.
- -o
Fügt existierende PDF-Dokumente (
inDocs...) zu einem neuen PDF-Dokument (outDoc) zusammen. Mit diesem Parameter müssen Sie einen Zieldateinamen und einen oder mehrere Ursprungsdateinamen bestimmen. Es ist möglich, nur ausgewählte Seiten von der Ursprungsdatei zur Zieldatei zu kopieren, indem Sie Seitenbereiche angeben. Gültige Seitenbereiche sind in Kapitel 6.1.2 „Operanden“ aufgeführt.- Wichtig:
-
Wenn der Name, den Sie für die Zieldatei auswählen, bereits im Zielverzeichnis vorhanden ist, wird die vorhandene Datei ersetzt!
- -a
Hängt ein PDF-Dokument, oder Teile davon, (
inDocs...) an das Ende eines anderen – schon bestehenden – PDF-Dokuments (outDoc) an.- -e
Kopiert entweder alle Seiten oder die Seiten, die Sie bestimmt haben, aus einem PDF-Dokument (
inDoc) heraus und erstellt neue Einzelseiten-PDF-Dateien. Bei der Anwendung dieses Parameters müssen Sie ein Prefix für die Zieldateien angeben. Die Seiten mit den Seitenzahlen<nnn>der Ursprungsdatei werden dann in ein neues PDF-Dokument mit dem Namen<prefix><nnn>.pdfkopiert.- -h
Hilfetext anzeigen.
6.1.2 Operanden
Nach jeder <inDoc> Angabe kann eine durch Komma getrennte Liste von
Bereichsfestlegungen folgen. Auf diese Weise können Sie sicherstellen, dass nur
die vorher festgelegten Seiten auf dem Ursprungsdokument genutzt werden:
- <a>
Nur Seite
<a>- <a>-<b>
Seite
<a>bis Seite<b>- <a>-
Seite
<a>bis letzte Seite- -<b>
Erste Seite bis
<b>
Das Zeichen „$“ steht für die letzte Seite eines Dokuments (in einer Shell muss „$“ mit einer „Escape-Sequenz“ gesetzt werden, da es sonst als Kommando interpretiert würde).
Folgt der Angabe <inDoc> eine Liste von Seitenbereichen, werden
nur die angegebenen Seiten von <inDoc> in die Zieldatei kopiert.
Per Vorgabe werden alle Seiten von <inDoc> kopiert.
- Beispiel 1:
$ pdfcat -o new.pdf doc1.pdf doc2.pdf,2,5-7
Schreibt alle Seiten des Dokuments „doc1.pdf“ und weiterhin die Seiten 2, 5, 6, 7 von Dokument „doc2.pdf“ in ein neues Dokument mit Namen „new.pdf“.
- Beispiel 2:
$ pdfcat -o new.pdf doc1.pdf,\$-1
Schreibt alle Seiten von Dokument „doc1.pdf“ in umgekehrter Reihenfolge in ein neues Dokument mit Namen „new.pdf“.
- Beispiel 3:
$ pdfcat -a tmp.pdf doc1.pdf,9-6
Hängt die Seiten 9, 8, 7, 6 (in dieser Reihenfolge) von Dokument „doc1.pdf“ an das bestehende Dokument mit Namen „tmp.pdf“.
- Beispiel 4:
$ pdfcat -e page doc1.pdf,-3
Schreibt die Seiten 1, 2, 3 von Dokument „doc1.pdf“ in neue Einzelseitendokumente, die die Namen „page1.pdf“, „page2.pdf“, „page3.pdf“ bekommen.
6.2 pdfform
Das Programm „pdfform“ erlaubt Ihnen das Auslesen von Formularfeldwerten eines PDF-Dokuments.
- Verwendung:
pdfform [-p <password>] <pdffile>
6.2.1 Optionen
- -p <password>
Kennwort zum Öffnen eines PDF-Dokuments. Dies wird benötigt falls
<pdffile>durch ein „Open Password“ geschützt ist.
- Beispiel:
$ pdfform /laura/base11_e.pdf Company=HELIOS Software GmbH Date=03-11-04 Priority=Urgent
Dieses PDF-Dokument enthält drei Text-Formularfelder. Das Feld
Companyhat den Wert „HELIOS Software GmbH“, das FeldDateden Wert „03-11-04“ und das FeldPriorityhat den Wert „Urgent“.
6.3 pdfinfo
Das Programm „pdfinfo“ bietet zwei Einsatzmöglichkeiten: Druckinformationen über
das PDF-Dokumentt <pdffile> ausgeben oder Objekte daraus extrahieren.
Im Informationsmodus sieht jede Ausgabezeile folgendermaßen aus:
section: key1=value1, key2=value2, ..., flag1, flag2, ...
Mögliche Bereiche sind General, Security, Profile,
Layer, Plate, OutputIntent, Color,
Font, PageLabel, MediaBox, CropBox,
BleedBox, TrimBox, ArtBox, Rotate,
Transparency, Pattern, Image und Form.
Die Ausgabe kann mit der Option -o eingegrenzt werden. Beachten Sie bitte,
dass PDF-Textstrings wie Informationen zu Titel und Autor nach UTF-8 gewandelt werden.
Im Extraktionsmodus können beliebige Objekte mit Objektnummer aus dem PDF-Dokument
pdffile nach „stdout“ extrahiert werden.
- Hinweis:
-
Der Extraktionsmodus ist nur für Fachleute geeignet, die über umfassendes Wissen bezüglich des Aufbaus von PDF-Dokumenten verfügen.
- Verwendung:
pdfinfo [-f <fromPage>][-t <toPage>][-o <sections>][-l <layer>] [-m][-v][-p <password>] <pdffile> pdfinfo [-x <objNo> | -s <objNo> | -d <objNo>][-i <intentNo>] [-p <password>] <pdffile> pdfinfo -h
6.3.1 Optionen
- -p
Kennwort zum Öffnen eines PDF-Dokuments. Dies wird benötigt falls
pdffiledurch ein „Open Password“ geschützt ist.
Informationsmodus:
- -f <from page>
Erste Seitenzahl für Schrift- und Farbinformation. Die Vorgabe ist 1.
- -t <to page>
Letzte Seitenzahl für Schrift- und Farbinformation. Die Vorgabe ist die letzte Seite.
- -o <sections>
Nur Informationen für den angegebenen Bereich ausgeben. Die Vorgabe ist
-o All. Dadurch werden alle verfügbaren Informationen ausgegeben.- -l <layer>
Ebenen aus- oder abwählen (siehe Kapitel 17 „Ebenen in PDF-Dokumenten“).
- -m
Ein anderes Ausgabeformat für Werte und Flags verwenden, welches zur Weiterverarbeitung geeignet ist.
- -v
Objektnummern von Bilddateien und Formularen anzeigen.
Extraktionsmodus:
- -x <objNo>
Objekt mit der Nummer
<objNo>extrahieren.- -s <objNo>
Einen Stream komprimiert aus dem Objekt mit der Nummer
<objNo>extrahieren.- -d <objNo>
Einen Stream unkomprimiert aus dem Objekt mit der Nummer
<objNo>extrahieren.- -i <intentNo>
ICC-Profile aus dem PDF/X-Ausgabeintent mit der Nummer
<intentNo>extrahieren. PDF-Dokumente haben normalerweise einen oder gar keinen PDF/X-Ausgabeintent, weshalb die Nummer für gewöhnlich 1 ist.
- Beispiel 1:
Die beiden Befehle sind gleichwertig:
$ pdfinfo Doc.pdf $ pdfinfo -o All Doc.pdf
- Beispiel 2:
Informationen zu allen Bildern in „Doc.pdf“ abrufen:
$ pdfinfo -o Image Doc.pdf # pdfinfo 5.0.0 Image: Page=18, BBox=207.6720/371.4596/ 264.3224/443.6887, Resolution=278.3387/593.1125, BPP=8, ColorSpace=DeviceGray, Filters=FlateDecode Image: Page=18, BBox=225.1510/387.2033/ 237.4971/397.1024, Resolution=194.9898/194.9960, BPP=8, ColorSpace=DeviceRGB, Filters=FlateDecode
- Beispiel 3:
Informationen zu Transparenzen in „Doc1.pdf“ abrufen:
$ pdfinfo -o Transparency Doc1.pdf # pdfinfo 5.0.0 Transparency: Page=1, Transparencies=no Transparency: Page=2, Transparencies=yes Transparency: Page=3, Transparencies=no Transparency: Page=ALL, Transparencies=yes
- Beispiel 4:
Informationen zu Füllmustern in „Doc2.pdf“ abrufen:
$ pdfinfo -o Pattern Doc2.pdf # pdfinfo 5.0.0 Pattern: Page=1, Patterns=yes Pattern: Page=2, Patterns=no Pattern: Page=ALL, Patterns=yes
Füllmuster werden als graue Flächen dargestellt, wenn ein PDF-Dokument mittels ImageServer umgewandelt oder in eine Warteschlange vom Typ „Druckvorschau“ ausgegeben wird. Siehe dazu auch Kapitel 2.4 „Bekannte Einschränkungen“.
6.4 pdfnote
Das Programm „pdfnote“ kennt drei Betriebsarten: Alle Kommentare in einem PDF-Dokument
<pdffile> auflisten, den Inhalt eines solchen Kommentars extrahieren oder
dem PDF-Dokument eine Textnotiz hinzufügen.
- Verwendung:
pdfnote -l [-p <password>] <pdffile> pdfnote -x <annot> [-n <page>][-p <password>] <pdffile> pdfnote [-n <page>][-r <location>][-s][-t <title>][-c <contents>] [-p <password>] <pdffile> pdfnote -h
6.4.1 Optionen
- -p <password>
Kennwort zum Öffnen eines PDF-Dokuments. Dies wird benötigt, falls
<pdffile>durch ein „Open Password“ geschützt ist.- -n <page>
Nummer der Seite, an der die Notiz eingefügt werden soll. Die Vorgabe ist
1(erste Seite).- -l
Listet alle Kommentare in einem PDF-Dokument auf.
- -x <annot>
Extrahiert den Inhalt eines Kommentars
<annot>von der gewählten PDF-Dokumentenseite.- -r <location>
Die Position der Notiz auf der Seite.
<location>wird folgendermaßen angegeben:<llx>:<lly>:<width>:<height>, wobei die linke untere x-Koordinate („llx“), die linke untere y-Koordinate („lly“), die Breite („width“) sowie die Höhe („height“) der rechteckigen Aussparung für die Notiz in der Einheit „Punkte“ angegeben wird.- -s
Bestimmt, dass die Notiz bereits geöffnet angezeigt wird.
- -t <title>
Überschrift
<title>erscheint im Titel der Notiz.- -c <contents>
Inhalt der Notiz. Wird
-cnicht angegeben, wird der Inhalt von „stdin“ gelesen.- -h
Hilfedatei anzeigen.
- Beispiel:
$ pdfnote -r 10:400 -t "Joe" -c "OK" Doc1.pdf $ pdfnote -r 10:10:200:200 -t "Info" Doc2.pdf < info.txt
6.5 pdftoeps
EPSF-Dateien können von verschiedenen Programmen (z. B. Illustrator oder Photoshop) erzeugt werden und eine unterschiedliche Struktur besitzen. Ein Einsatzbereich von „pdftoeps“ ist es, PDF als Austauschdateiformat verwenden zu können und das Programm zur Erzeugung von EPSF-Dateien gleichartiger Struktur aus den hereinkommenden PDF-Dateien zu nutzen. Dieses Hilfsprogramm steht nur Anwendern von ImageServer zur Verfügung.
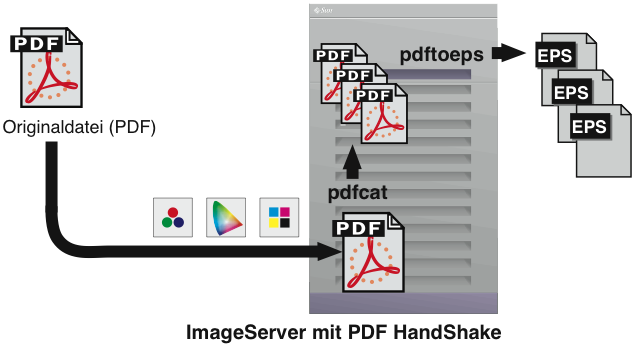
Wenn Sie in einer reinen EPSF-Umgebung arbeiten, aber PDF-Dateien von Ihren Kunden angeliefert bekommen, dann können Sie das „pdftoeps“-Programm verwenden, um die PDF-Dokumente in EPSF-Dateien umzuwandeln. Sie können für die Umwandlung den Zielfarbraum, die Auflösung und den Dateityp (Mac-EPSF oder PC-EPSF) vorgeben. Ein Anwendungsbeispiel für die „pdftoeps“-Nutzung sehen Sie in Abb. 6.1. Das Diagramm zeigt eine Situation, in der „pdfcat“ und „pdftoeps“ gemeinsam eingesetzt werden, um ein mehrseitiges PDF in mehrere Einzelseiten-EPSF-Dateien umzuwandeln.
Wir haben unserem Produkt 131 PostScript-3-Schriften beigelegt. Sie stehen nach der Installation und der korrekten Freischaltung von PDF HandShake automatisch zur Verfügung. Sie garantieren hohe Qualität im Ausdruck, in der Bildschirmdarstellung und in den Platzierungsbildern (bei der Verwendung von ImageServer). Die mitgelieferten Schriften sind im Anhang B „Mitgelieferte Schriften“ aufgelistet.
- Verwendung:
pdftoeps [options] <pdffiles> ... <destination>
6.5.1 Optionen
- -v
Zeigt Aktivitätsberichte während der Umwandlung von PDF zu EPSF an.
- -P <password>
Kennwort zum Öffnen eines PDF-Dokuments. Dies wird benötigt, falls
<pdffile>durch ein „Open Password“ geschützt ist.- -m
Erzeugt Mac EPSF-Dateien (vergl. auch Anhang C „Glossar“ und die Option
-punten).- -p
Erzeugt plattformübergreifende EPSF-Dateien (das Gegenteil der Option
-moben). Wenn keine der beiden Optionen festgelegt wird, hängt die Vorgabe davon ab, wo die gewählte PDF-Datei gespeichert ist und ob es sich bei dem Speicherort um ein Mac-Volume handelt. Wenn die Konfiguration des entsprechenden Volumes auf plattformübergreifende Platzierungsbilder eingestellt ist, dann sind auch die resultierenden EPSF-Dateien plattformübergreifend.- -r <resolution>
Stellt die Rasterauflösung in dpi ein, die für den druckfähigen Teil der EPSF-Voransichten verwendet werden soll. Dieser Parameter muss durch einen Fließkommawert (z. B. 72.0) ergänzt werden. Wenn Sie
-rnicht festlegen, wird die Rasterauflösung der Elemente der PDF-Eingangsdatei benutzt.- -c <colorspace>
Definiert den Farbraum, der für den druckfähigen Teil der EPSF-Voransichten verwendet werden soll. Der Parameter muss durch eine Zeichenkette, wie beispielsweise „CMYK“, ergänzt werden. Gültige Werte für Zeichenketten finden Sie in Tab. 6.1 unten. Wenn Sie
-cnicht festlegen, wird die Vorgabe des OPI-Servers benutzt.- -R <resolution>
Stellt die Rasterauflösung in dpi ein, die für die Bildschirmvorschau der EPSF-Datei verwendet wird. Dieser Parameter muss durch einen Fließkommawert (z. B. 72.0) ergänzt werden. Wenn Sie
-Rnicht festlegen, wird die Vorgabe des OPI-Servers benutzt.- -C <colorspace>
Definiert den Farbraum für die Bildschirmvoransicht der EPSF-Datei. Der Parameter erfordert eine Zeichenkette wie z. B. „Grayscale“. Gültige Werte für Zeichenketten entnehmen Sie bitte Tab. 6.1 unten. Wenn Sie
-Cnicht festlegen, wird der Standardfarbraum (RGB) verwendet.- -b <pagebox>
Zur Verfügung stehen:
MediaBox,CropBox,BleedBox,TrimBoxoderArtBox. Vorgabe ist „CropBox“.- -B
Erzeugt aus den Feindaten ein EPS-Rasterbild.
- -h
Hilfetext anzeigen.
Alle Optionen des „pdftoeps“-Programms sind optional. Sie sollten allerdings Parameter
wie -m oder -p genau festlegen, wenn Sie sich bei den aktuell
gültigen Standards nicht sicher sind.
Nach den Optionen müssen Sie eine oder mehrere Dateien zur Umwandlung sowie eine Zieldatei (wenn Sie eine Einzeldatei umwandeln) bzw. ein Zielverzeichnis (wenn Sie mehrere Dateien umwandeln) angeben. Das Ziel kann einen kompletten UNIX-Pfadnamen enthalten.
- Beispiel:
$ pdftoeps -m -c CMYK -C RGB file1 file2 /user/tmp
Das „pdftoeps“-Programm erkennt vorseparierte PDF-Dokumente. Es erzeugt DCS-Dateien mit farbigen Standard-Bildschirmvoransichten (abhängig von der Serverkonfiguration). Die Voransichten sind pixelbasiert und haben eine maximale Auflösung von 150 dpi.
Die DCS-Dateien sind als DCS-1- oder DCS-2-Mehrfachdateien gespeichert. Für die CMYK-Auszüge werden die Suffixe .C, .M, .Y und .K verwendet. Den Schmuckfarbenauszügen werden andere, bislang unbenutzte Buchstaben aus dem Alphabet zugewiesen. Das Suffix steht in keiner Beziehung zum Namen der Schmuckfarbe.
6.6 pdfprint
Mit „pdfprint“ können Sie PDF-Dateien direkt vom Server aus in eine HELIOS Druckerwarteschlange ausgeben (Abb. 6.2). Zusätzliche Eigenschaften wie Farbanpassung und Proofdruck stehen für jede Druckerwarteschlange zur Verfügung. Vorseparierte Dateien können nicht Composite ausgegeben werden. Diese Eigenschaft steht nur im OPI-Workflow zur Verfügung. Lesen Sie dazu bitte Kapitel 7.1 „pdfprint“.
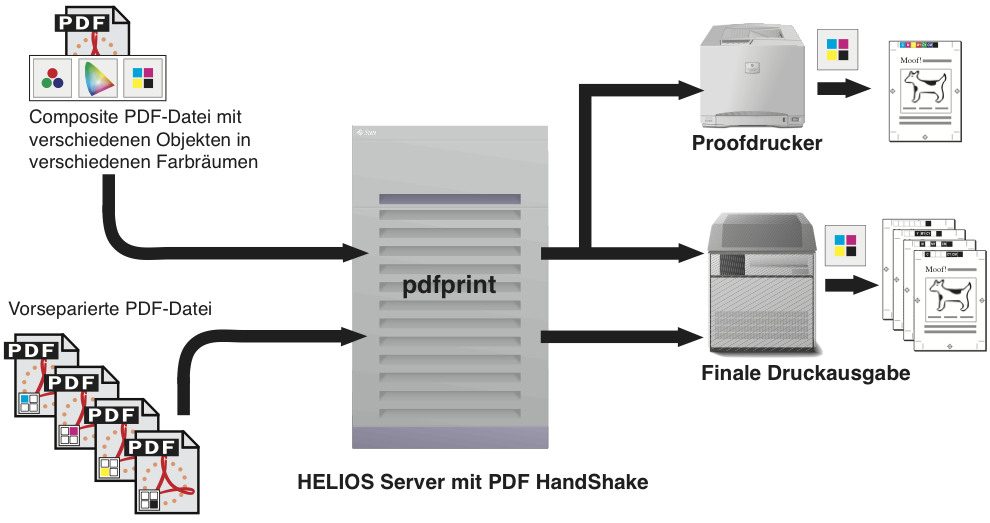
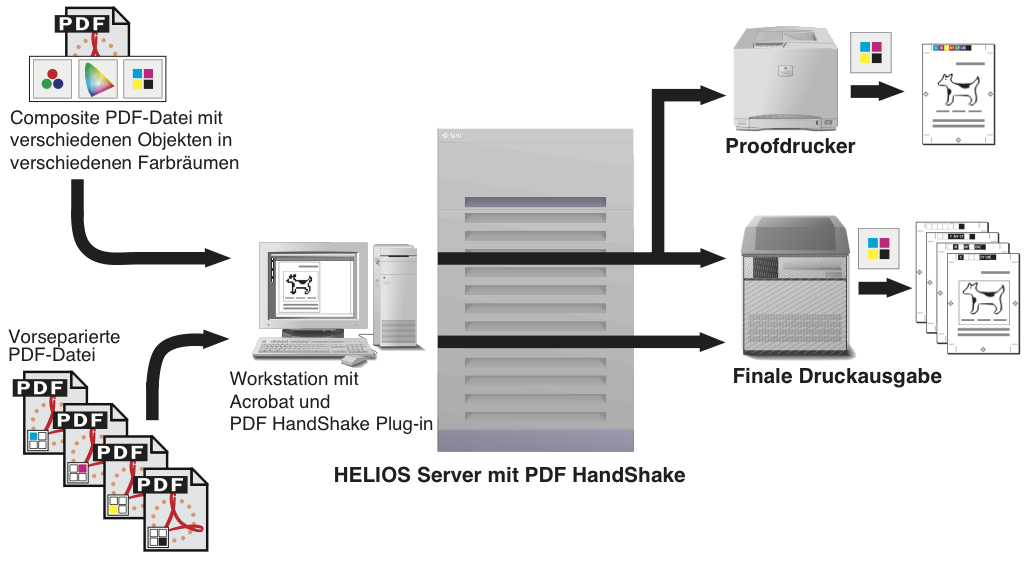
Das Plug-in für Acrobat (siehe 7.2 „PDF-Dateien mit dem Acrobat Plug-in drucken“) ist nur für den Mac verfügbar. Es hat die gleichen Eigenschaften wie das „pdfprint“-Programm und druckt genauso über jede EtherShare/PDF HandShake Druckerwarteschlange aus (Abb. 6.3). Auch hier können ohne die Nutzung von ImageServer vorseparierte PDF-Dateien nur als Auszüge ausgegeben werden.
Mit PDF HandShake und ImageServer können Sie das PDF-Dateiformat als Eingangsformat für die ImageServer-Layouterzeugung verwenden. Zusätzlich können Sie mit dem „PDF Handshake“ Acrobat Plug-in (oder dem „pdfprint“-Programm) PDF-Dateien zur weiteren Nutzung in Ausschießprogramme exportieren. Abb. 6.4 zeigt diese beiden Möglichkeiten in einem Überblick.
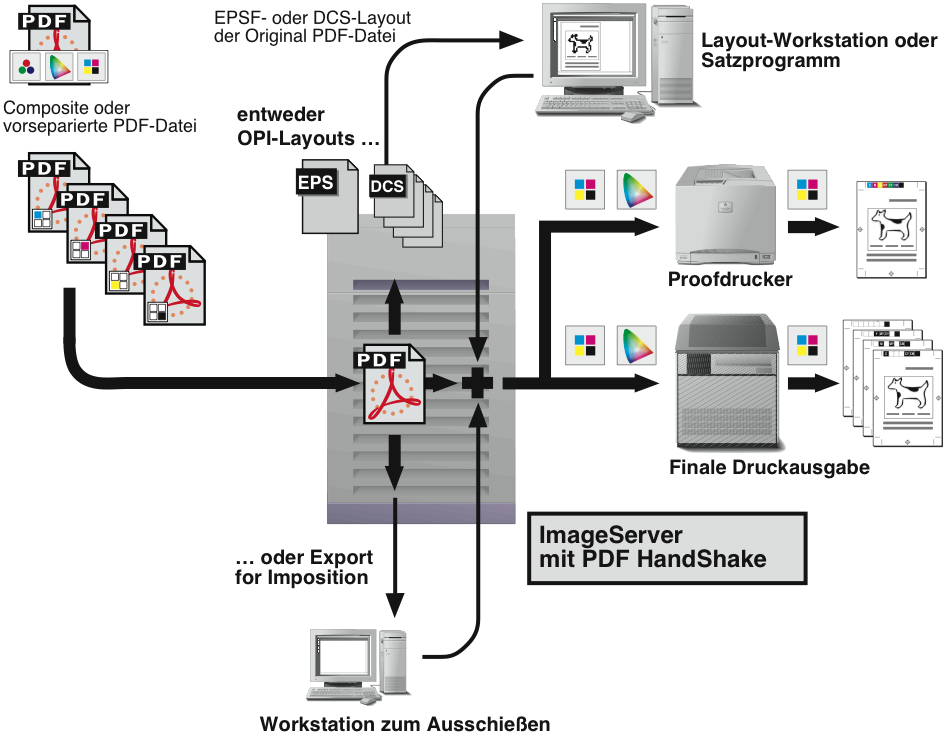
Der OPI-Server verwendet die erste Seite eines PDF-Dokuments für die Layouterzeugung. Weitere Seiten in der PDF-Datei werden ignoriert. Die erzeugten Platzierungsbilder werden für Composite-PDFs im EPS- sowie bei vorseparierten PDF-Dateien im DCS-Format gespeichert. So können Sie die Platzierungsbilder in jedem gängigen Layoutprogramm (wie QuarkXPress oder InDesign) sowie in jedem Anzeigen- und Redaktionssystem platzieren.
6.7 pdfresolve
Mit „pdfresolve“ können Sie OPI-Referenzen in PDF-Dokumenten auflösen. Programme wie QuarkXPress1 oder InDesign können Dokumente im eigenen Format (nativ) als PDF-Datei exportieren. Enthalten die nativen Dokumente OPI-Referenzen, können diese während des Exports beibehalten werden. Diese OPI-Referenzen werden verwendet, graue Platzhalter mit den hochaufgelösten Originalbildern vor oder während des Drucks zu ersetzen.
OPI 1.3 Referenzen enthalten den Pfadnamen der platzierten Bilddatei und zusätzlich eine optionale Mac Datei-ID. Während der Auflösung der OPI-Referenzen sucht „pdfresolve“ nach dem passenden hoch- oder niedrigaufgelösten Bild. Eine Bildsuche besteht aus einer Abfolge von Methoden: Suche über den Pfadnamen, Suche in zusätzlichen Suchpfaden, Suche über die Mac Datei-ID oder Suche in weiteren Volumes. Eine Bildsuche ist dann abgeschlossen, wenn eine der Methoden Erfolg hatte. Wird ein niedrigaufgelöstes Bild gesucht, wird das gefundene Bild für die Bildersetzung verwendet, unabhängig davon ob es eine hohe oder niedrige Auflösung besitzt. Wird ein hochaufgelöstes Bild gesucht und gefunden, wird es für die Bildersetzung verwendet. Wird dagegen ein hochaufgelöstes Bild gesucht, aber ein niedrigaufgelöstes gefunden, wird die OPI-Referenz des niedrigaufgelösten Bildes für eine weitere Bildsuche nach dem hochaufgelösten Bild benutzt. Eine Kette von niedrigaufgelösten Bildern, die auf ein hochaufgelöstes Originalbild verweisen, darf die Anzahl von sieben niedrigaufgelösten Bildern nicht überschreiten.
„pdfresolve“ hat den weiteren Vorteil, dass Transparenzen, die den Layoutbildern zugewiesen worden sind, währen der OPI-Bildersetzung beibehalten werden.
- Hinweis:
-
OPI-Referenzen in PDF-Dokumenten werden immer in Formular-Streams mit OPI-Einträgen eingebettet. Diese werden kurz OPI-Formulare genannt. „pdfresolve“ ersetzt OPI-1.3-Formulare in Composite PDF-Dokumenten; vorseparierte PDF-Dokumente werden nicht unterstützt. Es können nur Rasterbilder oder PDF-Dokumente referenziert werden; objektbasierte EPSF-Dateien werden nicht unterstützt. Die maximale Anzahl geöffneter Dateien für einen Prozess limitiert in etwa die Anzahl referenzierter PDF-Dokumente. In PDF-Dokumenten mit verschachtelten OPI-Referenzen wird nur die oberste Referenzebene ersetzt.
Bei OPI-Referenzen auf PDF-Dateien funktionieren nur Verweise auf die erste Seite des PDF-Dokuments.
Anweisungen dazu, wie ein überwachter Ordner („Hot Folder“) für PDF-natives OPI aufgesetzt wird, finden Sie in Kapitel 11 „PDF-nativer OPI-Workflow“.
„pdfresolve“ steht nur Anwendern von ImageServer zur Verfügung.
- Verwendung:
pdfresolve [-lv] -P <printer> [-g <logFile>][-o <key>=<value>]... <inDoc> <outDoc> pdfresolve -h pdfresolve -P <printer> -h (help info with printer parameters)
6.7.1 Optionen
- -l
Standardmäßig werden hochaufgelöste Bilder eingefügt. Ist diese Option gesetzt, werden niedrigaufgelöste Bilder, sofern vorhanden, eingefügt.
- -v
Zeigt den Fortschritt der Verarbeitung durch „pdfresolve“ an.
- -P <printer>
Ersetzt OPI-Objekte gemäß den Einstellungen für die Druckerwarteschlange
<printer>. OPI muss für die Warteschlange aktiviert sein. Diese Option muss zwingend angegeben werden.- -g <logFile>
Bei Warnungen oder Fehlermeldungen wird eine Logdatei
<logFile>mit Fehlerbeschreibung erzeugt.- -o <key>=<value>
Setzt einen Parameter-Key
<key>auf den Wert<value>.- -h
Hilfedatei anzeigen.
- -P <printer> -h
Hilfedatei mit Druckerparametern.
- Hinweis:
-
Kommandozeilen-Optionen haben eine höhere Priorität als dateispezifische Präferenzen, welche wiederum globale Präferenzen sowie Präferenzen für die Druckerwarteschlange überschreiben. Bei Parameter-Keys auf der Kommandozeile muss man – im Gegensatz zu Präferenzen – Groß- und Kleinschreibung nicht beachten.
6.7.2 Zulässige Parameter
- ImageSearchPaths <strlist:"">
Liste zusätzlicher Suchpfade. Eine Suche in zusätzlichen Pfaden macht Dateien mit passendem Grundnamen ausfindig.
- ImageIDsearch <bool:TRUE>
Bestimmt, ob Bilder mittels der Mac Datei-ID gesucht werden. Die Suche über die Datei-ID holt zuerst Informationen über die Art des Volumes aus der Datei-ID und sucht dann eine Datei mit passender Datei-ID in der Desktopdatenbank des angegebenen Volumes.
- ImageSearchVolumes <strlist:"">
Liste zusätzlicher Volumes, in denen gesucht wird. Die Suche in zusätzlichen Volumes benutzt die Desktopdatenbanken, um Dateien mit passendem Grundnamen zu finden. Dateien im Netzwerk-Papierkorb oder in Layoutordnern werden bei der Suche übergangen. Die Suche hat nur dann Erfolg, wenn es genau eine passende Datei gibt.
- CheckImages <bool:TRUE>
Wird diese Option auf
TRUEgesetzt, werden Fehlermeldungen für referenzierte, aber nicht vorhandene Bilder erzeugt. Ist die Option aufFALSEgesetzt, werden Warnungen für referenzierte, aber nicht vorhandene Bilder erzeugt und das OPI-Formular bleibt unverändert.- CheckRaster <bool:TRUE>
Per Vorgabe ist diese Option auf
TRUEgesetzt. Enthalten die referenzierten Bilder keine Rasterdaten in Druckqualität, wird ein Fehler ausgegeben. Wird diese Option aufFALSEgesetzt und enthalten die referenzierten Bilder keine Rasterdaten in Druckqualität, werden weder Fehler noch Warnungen ausgegeben.
Zur Verarbeitung von PDF-Dokumenten, die unter Verwendung von objektbasierten EPSF-Dateien erstellt wurden, muss diese Option folglich aufFALSEgesetzt werden.- RemoveOPI <bool:FALSE>
Legt fest, ob OPI-Referenzen von ersetzten Rasterbildern entfernt werden. OPI-Referenzen ersetzter PDF-Dokumente werden immer entfernt.
- ProfileRepository <str:"ICC-Profiles">
Gibt den Namen des Volumes an, welches die ICC-Profile beinhaltet. Ein ICC-Profil wird zuerst hier gesucht, und erst danach in den durch den Parameter
ProfileSearchPathsbestimmten Verzeichnissen.- ProfileSearchPaths <strlist:"">
Benennt zusätzliche Verzeichnisse, in denen ICC-Profile gesucht werden.
- CompositeColorspace <str:"CMYK">
Legt den Ausgabefarbraum für Quellbilder fest, deren Farbraum nicht Schwarzweiß oder Graustufen ist. Graustufenbilder sind nur dann betroffen, wenn sie eingefärbt und mit einem ICC-Profil verknüpft sind. Der Wert für diesen Parameter muss entweder
None,Grayscale,RGB,CMYKoderCIELabsein und mit dem Wert des ParametersDefaultPrinterProfileübereinstimmen, falls dieser gesetzt ist.- DefaultPrinterProfile <str:"">
Legt das Ausgabeprofil für Quellbilder fest, deren Farbraum nicht Schwarzweiß oder Graustufen ist. Graustufenbilder werden nur dann berücksichtigt, wenn sie eingefärbt und mit einem ICC-Profil verknüpft sind.
- PrintRenderingIntents
Legt die Strategie fest, die das Farbanpassungsmodul bei der Umwandlung zwischen beliebigen Quell- und Drucker-Farbräumen anwendet. Die Syntax ist:
<sourceA>:<printerA>:<intentA>,<sourceB>:<printerB>:<intentB>Nach: N S B G I R H H C C M D Y C C C C Y Von: None 3 3 3 3 3 3 3 3 0 0 3 3 3 3 3 3 3 3 Spot 3 3 3 3 3 3 3 3 0 0 3 3 3 3 3 3 3 3 Bilevel 3 3 3 3 3 3 3 3 0 0 3 3 3 3 3 3 3 3 Grayscale 3 3 3 3 3 3 3 3 0 0 3 3 3 3 3 3 3 3 Index 3 3 3 3 3 3 3 3 0 0 3 3 3 3 3 3 3 3 RGB 3 3 3 3 3 3 3 3 0 0 3 3 3 3 3 3 3 3 HSV 3 3 3 3 3 3 3 3 0 0 3 3 3 3 3 3 3 3 HLS 3 3 3 3 3 3 3 3 0 0 3 3 3 3 3 3 3 3 CMY 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 CMYK 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 Multitone 3 3 3 3 3 3 3 3 0 0 3 3 3 3 3 3 3 3 Duotone 3 3 3 3 3 3 3 3 0 0 3 3 3 3 3 3 3 3 YCbCr 3 3 3 3 3 3 3 3 0 0 3 3 3 3 3 3 3 3 CIELab 3 3 3 3 3 3 3 3 0 0 3 3 3 3 3 3 3 3 CIEXYZ 3 3 3 3 3 3 3 3 0 0 3 3 3 3 3 3 3 3 CIELuv 3 3 3 3 3 3 3 3 0 0 3 3 3 3 3 3 3 3 CIEYxy 3 3 3 3 3 3 3 3 0 0 3 3 3 3 3 3 3 3 YCC 3 3 3 3 3 3 3 3 0 0 3 3 3 3 3 3 3 3Zulässige Werte für das „Rendering Intent“ sind:
Perceptual (0)
Relative Colorimetric (1)
Saturation (2)
Absolute Colorimetric (3)
Perceptual mit BPC (4)
Relative Colorimetric mit BPC (5)
Saturation mit BPC (6)
- DefaultProofProfile <str:"">
Legt das Proofprofil für Quellbilder fest, deren Farbraum nicht Schwarzweiß oder Graustufen ist. Graustufenbilder werden nur dann berücksichtigt, wenn sie mit einem ICC-Profil verknüpft sind und die Standard OPI-Einfärbung aufweisen.
- ProofRenderingIntents
Legt die Strategie fest, die das Farbanpassungsmodul bei der Umwandlung zwischen beliebigen Quell- und Proof-Farbräumen anwendet. Die Syntax ist:
<printerA>:<proofA>:<intentA>,<printerB>:<proofB>,<intentB>Nach: N S B G I R H H C C M D Y C C C C Y Von: None 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 Spot 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 Bilevel 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 Grayscale 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 Index 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 RGB 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 HSV 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 HLS 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 CMY 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 CMYK 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 Multitone 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 Duotone 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 YCbCr 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 CIELab 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 CIEXYZ 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 CIELuv 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 CIEYxy 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 YCC 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3Zulässige Werte finden Sie oben (
PrintRenderingIntents).- DefaultDevLinkProfile <str:"">
Wenn kein
DefaultPrinterProfileangegeben wurde, hat diese Option keine Auswirkungen. Mit dieser Option lässt sich ein DeviceLink ICC-Profil setzen, dessen Ausgabefarbraum mit dem Farbraum vonDefaultPrinterProfileübereinstimmen muss. Sind sowohlDefaultPrinterProfileundDefaultDevLinkProfilegesetzt, wird für alle Quellbilder, deren Farbraum mit dem Eingangsfarbraum des DeviceLink ICC-Profils übereinstimmt, eine Farbanpassung gemäß dem DeviceLink ICC-Profil vorgenommen.- RenderingQuality <int:2>
Bestimmt die Qualität der Farbanpassung über CMM. Der Wert muss
0(Normal),1(Entwurf) oder2(Maximal) sein.- CheckICCProfiles <bool:TRUE>
Legt fest, ob für fehlende ICC-Profile Fehlermeldungen erzeugt werden sollen.
- IgnoreUntagged <bool:FALSE>
Ist
DefaultPrinterProfilenicht gesetzt oderCheckICCProfilesinaktiv, wirkt sich diese Option nicht aus. Diese Option bestimmt, ob Fehlermeldungen für farbige Quellbilder erzeugt werden, die nicht mit einem ICC-Profil versehen sind und die nicht durch die OptionDefaultPrinterProfilevon der Farbanpassung ausgenommen werden.- PureBlack <bool:FALSE>
Legt fest, ob schwarze Pixel von der Farbanpassung ausgenommen werden.
- PureWhite <bool:FALSE>
Legt fest, ob weiße Pixel von der Farbanpassung ausgenommen werden.
- PureGrays <bool:FALSE>
Legt fest, ob graue Pixel von der Farbanpassung ausgenommen werden.
- PureCMY <bool:FALSE>
Legt fest, ob reine Cyan-, Magenta- und Gelbpixel bei der Wandlung von CMYK zu CMYK von der Farbanpassung ausgenommen werden. Reine Cyanpixel bestehen zu 100 Prozent aus Cyan und 0 Prozent aus anderen Farben. Reine Magenta- und Gelbpixel werden gleichermaßen definiert.
- PDFPageBox <crop box>
Legt fest, ob eine Pagebox bei der OPI-Bildersetzung von hochaufgelösten PDF-Bildern verwendet wird. Zur Verfügung stehen:
MediaBox,CropBox,BleedBox,TrimBoxundArtBox.- TagReplacedImages <bool:FALSE>
Legt fest, ob ersetzte Bilder – wenn möglich – mit ICC-Profilen versehen werden. Ist diese Option aktiviert und ein Druckerprofil definiert, so wird ein ersetztes Farbbild mit dem Drucker- oder Proofprofil versehen. Ist diese Option aktiviert und kein Druckerprofil definiert, so wird ein ersetztes Farbbild mit dem Profil des Quellbildes versehen, falls keine Farbumwandlung erforderlich ist.
- IgnoreSpots <bool:FALSE>
Legt fest, ob sämtliche Schmuckfarben in Quellbildern ignoriert werden. Werden Schmuckfarben nicht ignoriert, werden Sie in Prozessfarben gewandelt, es sei denn der Farbraum des Quellbildes ist CMYK mit zusätzlichen Kanälen für Schmuckfarben und
PreserveDeviceNist gesetzt.- CustomColorTinting <bool:TRUE>
Legt fest, ob Schmuckfarben aus eingefärbten Schwarzweiß- und Graustufenbilder erzeugt werden, falls die Einfärbung den Farbraum DeviceN nicht benötigt. Um Schmuckfarben auch im Farbraum DeviceN beizubehalten, muss sowohl die Option
CustomColorTintingals auchPreserveDeviceNaktiviert sein.- PreserveDeviceN <bool:FALSE>
Legt fest, ob aus Quellbildern im CMYK-Farbraum Bilder im DeviceN-Farbraum mit zusätzlichen Kanälen für Schmuckfarben erzeugt werden. Werden Bilder im DeviceN-Farbraum erzeugt, ist die Farbanpassung abgeschaltet.
- ColorAliases <strlist:"">
Liste von Alias-Farbnamen. Die Ersetzung von Farbnamen wird auf die Namen von Prozess- und Schmuckfarben in Quellbildern und OPI-Referenzen angewandt. Die Syntax ist:
<nameA>=<aliasA>,<nameB>=<aliasB>,...- DownSampling <bool:FALSE>
Bestimmt, ob die Auflösung eines Bildes reduziert wird. Schwarzweißbilder werden nicht heruntergerechnet.
- FixedSampling <bool:FALSE>
Ist die Reduzierung der Auflösung eines Bildes nicht aktiviert, bleibt diese Option ohne Auswirkung. Ist die Reduzierung der Auflösung aktiviert, bestimmt diese Option, ob das Hochrechnen von Bildern möglich ist.
- FastDownSampling <bool:FALSE>
Bestimmt, ob der „schnelle-Auswahl“-Algorithmus oder der Mittelwert-Algorithmus zum Herunterrechnen verwendet wird. Erstgenannter ist schnell bei minderer Qualität während der Mittelwert-Algorithmus langsamer ist aber dafür eine hohe Qualität bietet.
- Resolution <double:0.000000>
Bestimmt die Auflösung (in dpi) eines Bildes beim Herunterrechnen. Der angegebene Wert muss positiv sein.
- ICMethodBilevel, ICMethodGrayscale, ICMethodRGB, ICMethodCMYK, ICMethodCIELab, ICMethodOther <str:"None">
Diese Parameter bestimmen die Komprimierungsmethode für Bilder im entsprechenden Ausgabefarbraum. Der Wert muss entweder
None,Compress,CCITTG4,JPEG,JPEG 2000oderFlatesein.- ICQualityBilevel, ICQualityGrayscale, ICQualityRGB, ICQualityCMYK, ICQualityCIELab, ICQualityOther <siehe Text>
Diese Parameter bestimmen die Qualität der JPEG- und JPEG 2000-Komprimierung für Bilder im entsprechenden Ausgabefarbraum. Der Typ ist
doublezwischen0und100.Für JPEG:
<double:75>
Erzeugt Bilder in geringer…höchster Qualität (1…100).Für JPEG 2000:
<double:0>
Legt die Bildqualität eines JPEG-2000-Bildes in Bezug auf das unkomprimierte Originalbild fest. Es können Werte von 1…100 angegeben werden. Die Angabe „0“ bedeutet verlustfrei.- Hinweis:
-
Eine Beschreibung zum Setzen von Downsampling- und Komprimierungsmöglichkeiten für Druckerwarteschlangen finden Sie in Kapitel 11.3.1 „Downsampling und Komprimierung“.
6.7.3 OPI-Einstellungen für „pdfresolve“ über Präferenzen
Wird für den „pdfresolve“-Workflow eine eigene Druckerwarteschlange eingerichtet (kein Drucken über PostScript) kann auch das Bildformat JPEG 2000 verwendet werden. Hierfür müssen jedoch die entsprechenden Präferenzen von Hand gesetzt werden, z. B.:
# prefvalue -k "Printers/DRUCKER/PostScriptImage/CIELab/CompressPostScript"
-t str "JPEG 2000"
# prefvalue -k "Printers/DRUCKER/PostScriptImage/CMYK/CompressPostScript"
-t str "JPEG 2000"
# prefvalue -k "Printers/DRUCKER/PostScriptImage/Grayscale/
CompressPostScript" -t str "JPEG 2000"
# prefvalue -k "Printers/DRUCKER/PostScriptImage/RGB/CompressPostScript"
-t str "JPEG 2000"
Die Präferenz CompressPostScript wird im ImageServer Handbuch im Kapitel
„OPI-Druckerpräferenzen“ dokumentiert.
- 1 ab QuarkXPress 10 kein OPI-Support mehr